Building a JavaScript Library Part 1: DOM Selecting
In this series we will be building a basic JavaScript library for the most common tasks that we do. So, like any good project should, let’s start with our library’s requirements:
- IE8+ Compatible
- Work in browsers and in nodeJs.
- Synchronous and asynchronous design pattern.
- Limited pollution of Global scope
- no global & or _ object that will conflict with popular libraries
and our Goals:
- Faster than jQuery on similar tasks.
- Smaller than jQuery
- Modular
- Not to suck too bad.
“Without requirements or design, programming is the art of adding bugs to an empty text file.”
- Louis Srygley
Notice: The intended purpose of the library is as a teaching tool, it is not intended to be used in a production environmental this time (or maybe ever). You’ve been warned!!
Document Object Model (DOM)
By far the most common task that JavaScript developers perform is manipulation HTML/XML elements. In JavaScript HTML/XML elements are controlled by the Document Object Model (DOM). The DOM object is stored as the document object in global scope (window) when running JavaScript in a browser. It can be called via document or window.document. The DOM stores all of the HTML/XML elements in a given scope (window) and the properties to manipulate those elements.
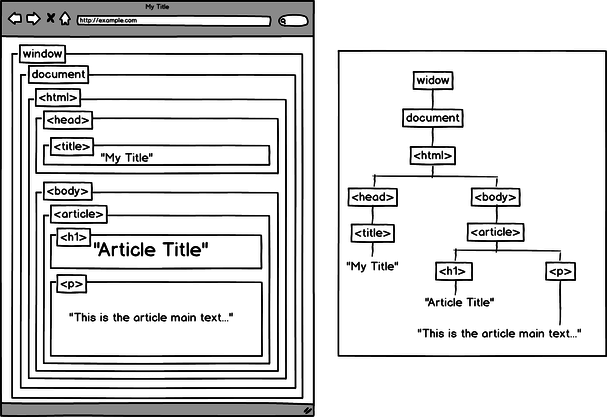
Note:
Command line JavaScript tools like NodeJS do not have a document object instantiated by default.
Before we can start doing fun stuff with DOM elements you must first be able to target them. You could traverse the document object like document.body.children which returns a list of direct children that can then be traversed similarly, but that can get tedious and costly rather quickly. Fortunately JavaScript provides us with some excellent tools for finding things in the dom. The five most useful are: getElementById(), getElementsByClassName(), getElementsByTagName(), getElementsByName(), and querySelector() / querySelectorAll(). These methods can be used on any DOM element, i.e. document any of it’s children.
Use the following code for all quering examples.
<!DOCTYPE html>
<html>
<head>
<title>Selecting DOM Elements</title>
</head>
<body>
<p id="para1">Some text here</p>
<p id="para2">
<ul class="unorderdList" >
<li></li>
<li></li>
<li></li>
</ul>
</p>
<button" name="red">red</button>
</body>
</html>
.getElementById()
[element].getElementById() returns a single element that matched the given id or null if none can be found. Two thing that you will need to take note of: If you are used to jQuery or other such libraries you will notice there is no # sign in front of the id name. That’s right css selectors don’t work here it needs to match the element attribute exactly. On that note, the second thing to remember: it IS case sensitive.
var element = document.getElementById('para1');
.getElementsByClassName()
[element].getElementsByClassName() returns a HTMLCollection of HTMLElements that matched the given class(es) name or null if none can be found. Again case sensitive, no . at the beginning of the class(es) and you can list multiple classes separated by spaces.
var element = document.getElementsByClassName('unorderdList');
.getElementsByTagName()
[element].getElementsByTagName() returns a Live HTMLCollection of HTMLElements that matched the given element’s name (eg: p for <p> tag) or null if none can be found. Not case sensitive and the list is a live list, which means it updates to match changes in the DOM automatically.
var element = document.getElementsByTagName('li');
Note: There is some browser inconsistency with the return type of document.getElementsByTagName(). Some version of WebKit browsers returns a NodeList object instead of a HTMLCollection object.
.getElementsByName()
[element].getElementsByName() returns a NodeList of HTMLElements that matched the given element’s name attribute. If no matches can be found null is returned This one is case sensitive.
var element = document.getElementsByName('red')
Note: There is some browser inconsistency with [element].getElementsByName(). Some browsers include matching id attributes, while other do not. Also some browsers ignore elements that have a name attribute that are not supported.
.querySelector() / .querySelectorAll()
If you are familiar with jQuery you will recognize the syntax. The heart of jQuery’s Sizzle selector engine is built around [element].querySelectorAll(). [element].querySelectorAll() returns a non-live NodeList of HTMLElements that match the CSS selector that were passed.
var element = document.querySelectorAll('#para2 li');
Note: It will only work with valid CSS 2+ selectors, jQuery uses some CSS selectors that are non standard (eg, :first) that will not work with .querySelectorAll().
Performance
To test the performance of the methods above: I prepared a jsperf.com benchmark: http://jsperf.com/querying-dom-elements/2
As you can see, selecting a single element is faster than selecting a bunch of elements, which makes sense. You should also note that .querySelector() / .querySelectorAll() is significantly slower that all of the others.
select()
Now that we have covered the basics of selecting an element, we need to write our first function for our library. Since most of us are familiar with using CSS selectors for targeting elements, we will build our select() function around that premise. Again lets define our requirements/design:
- a selector parameter
- an option to change the scope
- return a normalized list of elements
or
- pass results as a parameter on the callback function
querySelectorAll() only
Now that we have our specs lets write the function:
function select(selector, scope, callback) {
var _scope = scope || document,
_results = _scope.querySelectorAll(selector);
if (typeof callback === 'function') {
callback(null, _results);
} else {
return _results;
}
}
That is pretty simple, it works on all the browsers on my box. In our example we have created a function that accepts three parameters: the CSS selector parameter, the optional HTMLElement scope parameter, and the optional callback function. Inside the function a variable _scope is created and set to the value of scope or document if scope is not set. The second variable that is created is _results and is set to the results of the scoped querySelectorAll() with the give selector. Finally we check to see if a callback function was passed if so call the callback with the results or if not return the results.
Performance
Let’s test it and see how we did. I have setup another jsperf.com benchmark test for us:
http://jsperf.com/queryselectorall-vs-select
Not so hot. We roughly double the amount of time it takes to run a querySelectorAll() call with no real benefit. We are beating jQuery on the #Test but that it. I think we can do better.
querySelectorAll() + getElementsByClassName() + getElementById()
If you remember some of the other methods were a lot faster than querySelectorAll(). Lets use them to see if we can boost performance. For now we are going to focus on the performance of selecting by class and by id as they are the most common way to select elements.
Check for ID and use getElementById()
We’re going to begin by using getElementById() to select elements when we are given only an id. To do that we need to check if the string selector starts with a # sign, doesn’t contains spaces or periods (.). For that we use one of the string functions .indexOf() that checks for the first occurrence of a string inside another string and returns the array index of the occurrence or -1 of not found.
If you remember getElementById() doesn’t like the # sign. We need to remove it before we can us it. There are a number of ways to do that, but I like the .slice() method for strings. slice(x) removes the first x number of characters from a string. It can also be used to take a chuck out of the middle of a string by adding a second parameter like:
var selector = '#selector_D';
var sliced = selector.slice(1) // sliced = 'selector_D'
var sliced2 = selector.slice(1, 9) // sliced2 = 'selector'
//negative values remove remove from the end
var sliced3 = selector.slice(-2) // sliced3 = '#selector'
var sliced4 = selector.slice(1, -2) // sliced4 = 'selector'
Now our function should look something like:
function select(selector, scope, callback) {
var _scope = scope || document,
_results;
if (selector.indexOf("#") === 0 && selector.indexOf(" ") === -1 && selector.indexOf(".") === -1) {
_results =_scope.getElementById(selector.slice(1));
} else {
_results = _scope.querySelectorAll(selector);
}
if (typeof callback === 'function') {
callback(null, _results):
} else {
return _results;
}
}
Check for Class(es) and use getElementsByClassName()
Checking for class names is a little more difficult, but not much because, we just need to check for a . at the beginning, that it doesn’t contain a # sign or a colon. This time we are replacing the . with a space because getElementsByClassName() can accept multiple classes separated by space. To do that we are using the string.replace(/./g, " ") method and a regular expression that looks for a . globally.
function select(selector, scope, callback) {
var _scope = scope || document,
_results;
if (selector.indexOf("#") === 0 && selector.indexOf(" ") === -1 && selector.indexOf(".") === -1) {
_results =_scope.getElementById(selector.slice(1));
} else if (selector.indexOf(".") === 0 && selector.indexOf("#") === -1 && selector.indexOf(":") === -1) {
_results =_scope.getElementsByClassName(selector.replace(/./g, " "));
} else {
_results = _scope.querySelectorAll(selector);
}
if (typeof callback === 'function') {
callback(null, _results):
} else {
return _results;
}
}
Results Normalization
We’re getting closer, but we still have a problem with different return types. getElementById() returns a single HTMLElement, getElementsByClassName() returns a HTMLCollection, and querySelectorAll() returns a NodeList. We need to normalize or return results so it is the same regardless where it comes from. By far the easiest thing to standardize to is an array. It is really easy with getElementById(), all we have to do is wrap it in array notation (ie. surround it with square braces [] ) like so _results = [_scope.getElementById(selector.slice(1))]; . For the other two we need to do a little more fancy solution: [].slice.call(object). [].slice.call(object) converts an object to an array. How it does that is a bit out of the scope of this article. If you are interested there are plenty of articles about it that are googleable.
function select(selector, scope, callback) {
var _scope = scope || document,
_results;
if (selector.indexOf("#") === 0 && selector.indexOf(" ") === -1 && selector.indexOf(".") === -1) {
_results = [_scope.getElementById(selector.slice(1))];
} else if (selector.indexOf(".") === 0 && selector.indexOf("#") === -1 && selector.indexOf(":") === -1) {
_results = [].slice.call(_scope.getElementsByClassName(selector.replace(/./g, " ")));
} else {
_results = [].slice.call(_scope.querySelectorAll(selector));
}
if (typeof callback === 'function') {
callback(null, _results);
} else {
return _results;
}
}
Final Function
As a final measure for backwards compatibility I added a check for single alphabet character words to run through getElementsByTagName() before defaulting to querySelectorAll(). My tests show that the regular expression eats up any performance gain by using getElementsByTagName() to get tags, but it really doesn’t cost me anything but a few extra bites of storage.
function select(selector, scope, callback) {
var _scope = scope || document,
_results;
if (selector.indexOf("#") === 0 && selector.indexOf(" ") === -1 && selector.indexOf(".") === -1) {
_results = [_scope.getElementById(selector.slice(1))];
} else if (selector.indexOf(".") === 0 && selector.indexOf("#") === -1 && selector.indexOf(":") === -1) {
_results = [].slice.call(_scope.getElementsByClassName(selector.replace(/./g, " ")));
} else if ( /^[a-zA-Z]+$/.test(selector)) {
_results = [].slice.call(_scope.getElementsByTagName(selector));
} else {
_results = [].slice.call(_scope.querySelectorAll(selector));
}
if (typeof callback === 'function') {
callback(null, _results);
} else {
return _results;
}
}
Performance
So how did we do? Well according to the http://jsperf.com/queryselectorall-vs-jquery-vs-select/2 benchmark test we average better than querySelectorAll() , and we beat jQuery in every test. Are we as robust as the jQuery’s Sizzle engine. Oh heck no. But that wasn’t the point of todays exercise. We are after Knowledge and Power!!
Until next time, Hack On!!